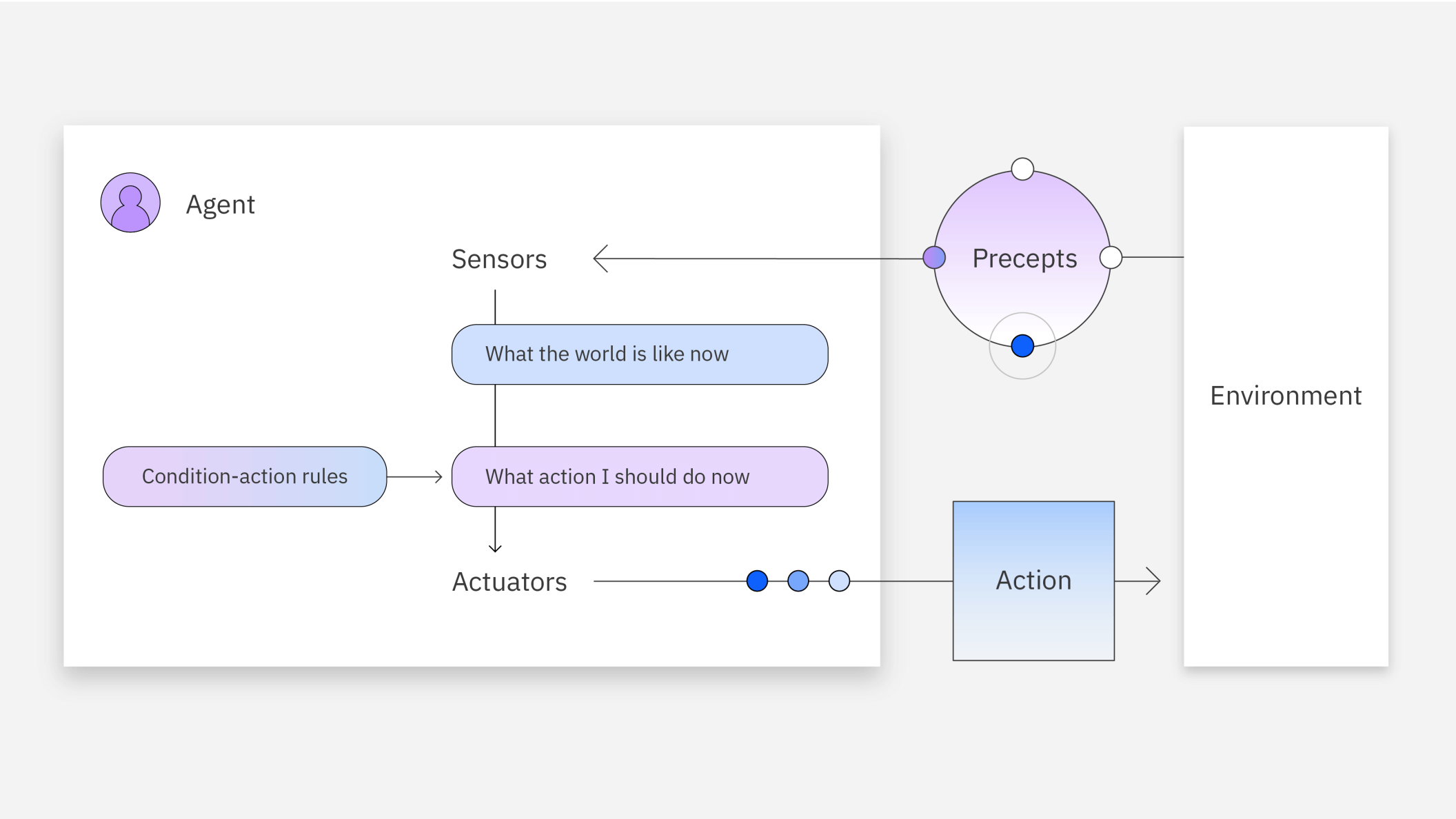
Perceive
Acquire context from search, APIs, files, or the screen; materialize a working memory.
Hydrate memory via retrieval/APIs/sensors.
Normalize state for grounded and auditable reasoning.
Agents demystified
Think of an agent as a controllable teammate: it reads what you allow, reasons through the request, and takes approved actions. This guide explains how it works, the design trade-offs, and how to run it safely.
Perceive first
Establish facts from documents, APIs, or the screen before planning or acting.
Reason simply, then deeply
Begin with a minimal plan; add deliberate loops for ambiguous or long tasks.
Act safely
Each tool call carries intent, scoped permissions, logging, and rollback.
Operate continuously
Maintain observability and human oversight; refresh memories on schedule.
Acquire context from search, APIs, files, or the screen; materialize a working memory.
Hydrate memory via retrieval/APIs/sensors.
Normalize state for grounded and auditable reasoning.
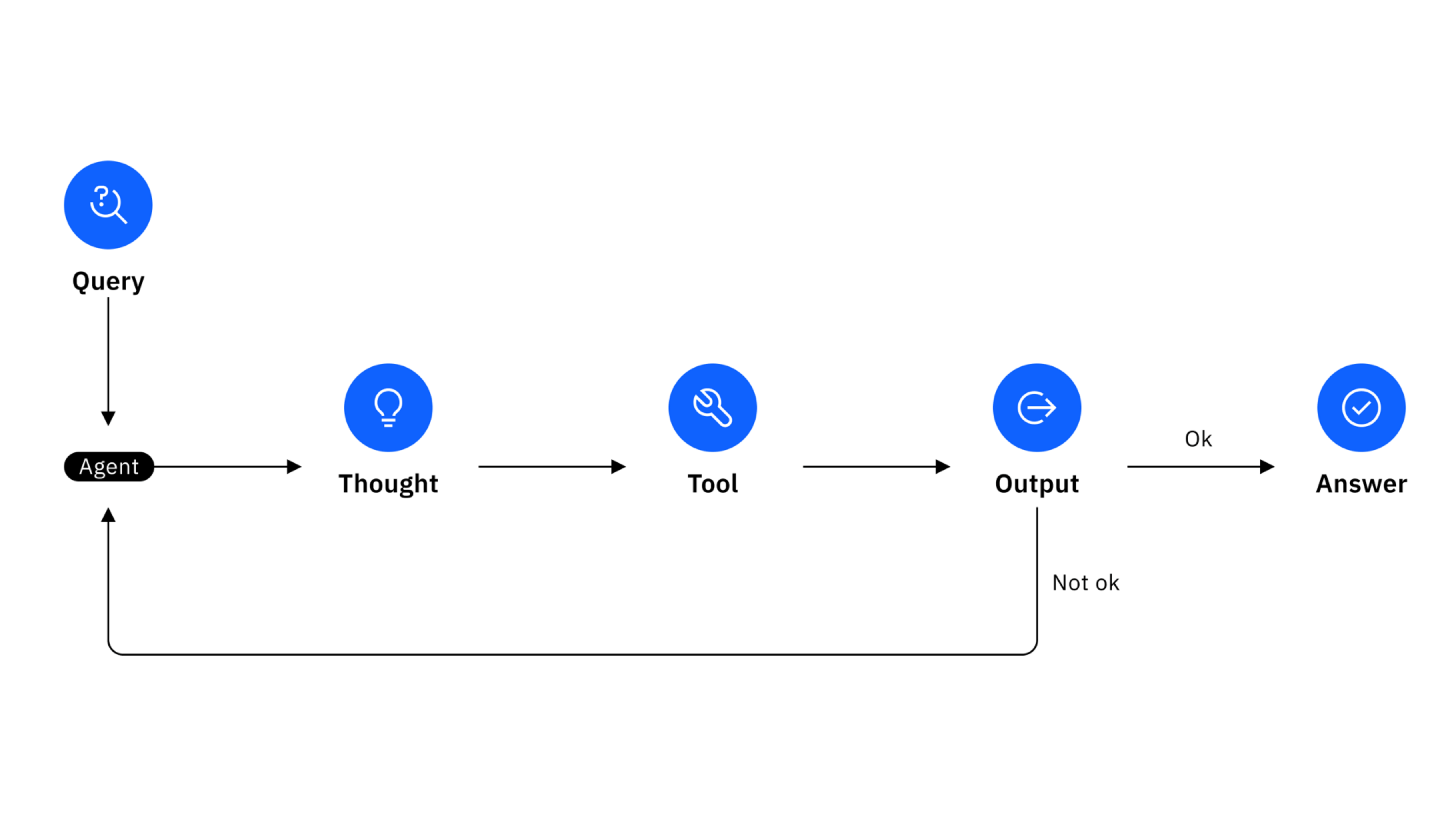
Translate goals into steps; combine heuristics with deliberate loops as needed.
Mix fast heuristics with tool-using reflections.
Use guardrails to prevent overreach and error accumulation.
Invoke tools/services with explicit intent and scoped permissions; trace all steps.
Transaction logs and rollbacks bound autonomy.
Evaluate outcomes to improve reliability and trust.
Collect domain knowledge, live signals, and constraints; hydrate episodic and semantic memories with clear TTLs.
Knowledge base, connectors, data contracts
Draft a task graph, assign tools, simulate risky steps, and establish approvals/limits.
Task graph, guardrail policy, evaluation hooks
Run steps with tracing; stream outputs; each call includes intent, scope, and rollback.
Tool adapters, workflow runners, audit log
Score outcomes, refresh memories, correct drifts, and escalate when confidence is low.
Offline evaluation, memory compaction, feedback loops
Model choice determines depth, latency, and cost; reserve stronger models for hard steps.
Frontier & compact models; structured multi-step reasoning
Select via task-level evaluations, not hype
Coordinate memory, tools, and state; prefer stateful graphs and resumable runs.
Stateful graphs; open tool protocols (e.g., MCP)
Policies/permissions and traces as first-class concerns
Define boundaries and approvals; implement programmable guardrails.
Guardrails (e.g., Colang), rate limits, content filters
Human checkpoints for high-risk actions
Operate like software: tracing, evaluations, canaries, and rollback.
Observability platforms; dataset-based evaluations
Cost/latency dashboards and continuous improvement
Shared planners, specialized workers, and human checkpoints let you compose reliable agent teams.
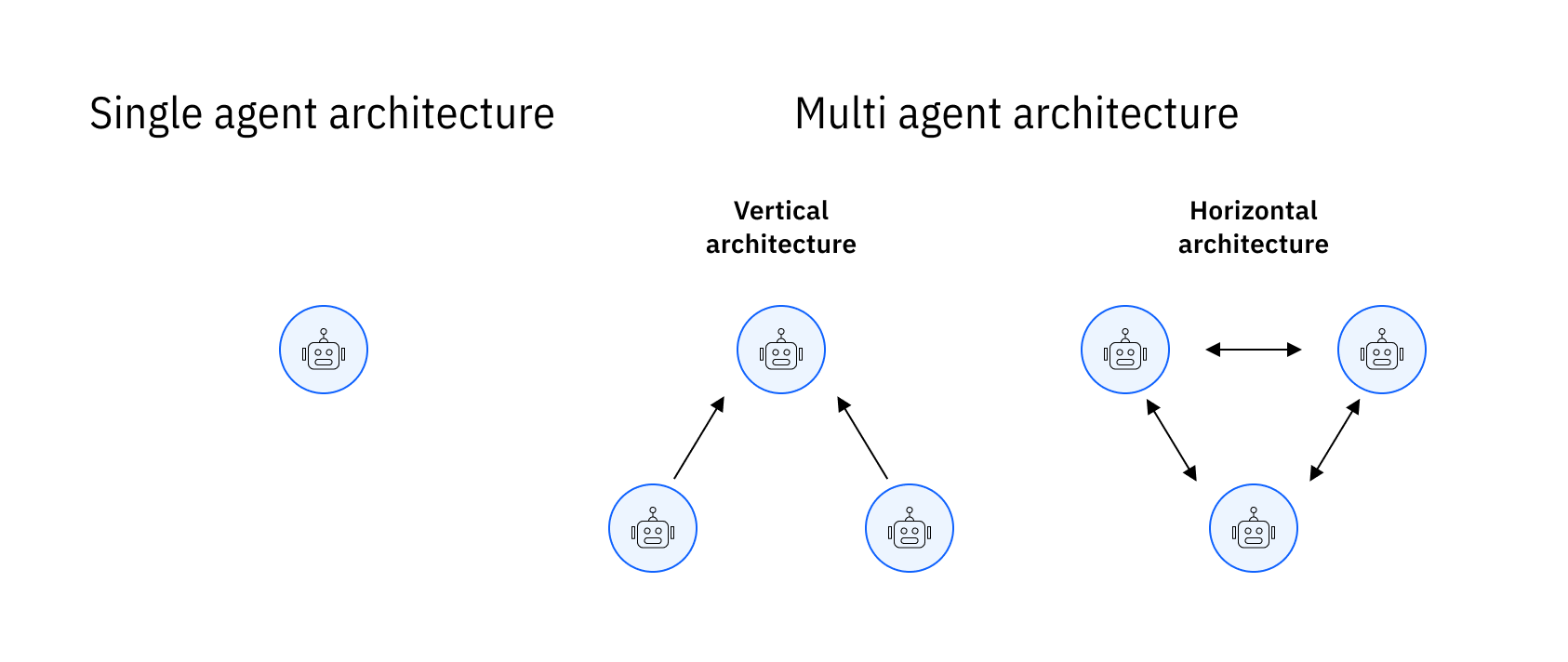
One planner coordinates multiple specialist agents with shared memory and guardrails.
Keeps tooling centralized, easier to audit.
Escalate to humans when planner confidence drops.
A router selects from a pool of agents based on skill tags and historical performance.
Requires consistent scoring and rate limits per agent.
Cache frequent tasks to reduce selection latency.
Long-running workflows pair agents with named human roles for approvals or final delivery.
Surface context packs for humans to act quickly.
Log human decisions back into agent memory.
Curated by an automated monitor that scrapes vendor blogs, research feeds, and policy trackers.
The new O4-Mini model focuses on short-horizon planning with tool calling baked in, offering better latency for production agents.
Claude Ops released an open benchmark to profile perception, planning, and action latencies across orchestration stacks.
A draft regulation would require transparent logging and reversible actions for high-autonomy systems deployed in Europe.